 И вторая мегачасть про различия между C# и VB.NET:
И вторая мегачасть про различия между C# и VB.NET:В первой части статьи тема превосходства VB.NET над C# по рейтингу TIOBE нашла живой отклик в комментариях. Поэтому по совету AngReload посмотрим на тренды StackOverflow.
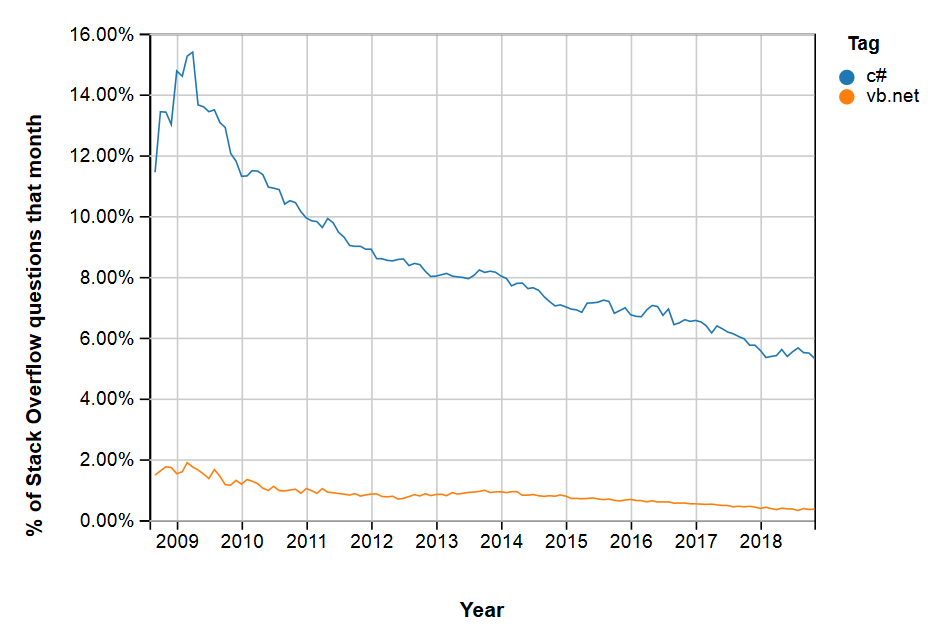
C# все еще силен! Революция, о которой так долго говорили в прошлый раз, отменяется! Ура, товарищи! Или нет? Рейтинг TIOBE строится на основе запросов в поисковиках, а рейтинг SO — на основе тегов задаваемых вопросов. Возможно, разработчики VB.NET, в число которых входит множество людей не айти специальностей, просто не знают о существовании StackOverflow? Или попав туда через гугл, а то и Bing, не понимают, как задать вопрос? А может быть им достаточно документации Miscrosoft, а все немногочисленные вопросы уже отвечены.
Так или иначе, доля VB.NET заметна и стабильна, пусть и не на первом месте по объему. И, конечно, такой результат был бы невозможен без сильной команды проектировщиков и разработчиков языка. Ниже — вторая часть перевода статьи участника этой команды, Энтони Грина.
Содержание
Скрытый текст
Преобразования
34. Булевы преобразования
Преобразование
Boolean True в любой знаковый числовой тип выдает -1, а в любой беззнаковый — максимальное значение для этого типа, тогда как в C# таких преобразований не существует. Однако метод Convert.ToInt32, например, преобразует True в 1, и именно так он чаще всего представлен в IL. В обратном направлении любое число, отличное от 0, преобразуется в True.Почему? Причина, по которой VB предпочитает использовать от
-1 до 1, заключается в том, что побитовое отрицание 0 (все биты установлены в 0) на любом языке равно -1 (все биты установлены в 1), поэтому использование этого значения объединяет логические и побитовые операции, такие как And, Or и Xor.Также поддерживаются преобразования в и из строк «True» и «False» (разумеется, без учета регистра).
35. Преобразования между типами Enum, а также между типами Enum и их базовыми типами полностью неограничены, даже если Option Strict выставлено в On
С философской точки зрения язык относится к
Enum-типам скорее как к набору именованных констант базового целочисленного типа. Место, где это наиболее очевидно, — равенство. Всегда допустимо сравнивать любое целое число со значением перечисления, тогда как в C# это дает ошибку.Время историй: API Roslyn прошел много внутренних ревизий. Но в каждой из них для каждого языка было выделено перечисление
SyntaxKind, которое говорит вам, какую синтаксическую конструкцию представляет узел (например, IfStatement, TryCastExpression). Однажды разработчик использовал API, которое пыталось абстрагироваться от языка и возвращало одно из значений SyntaxKind, но только как Integer, и, не получив ошибки при сравнении сырого Integer и SyntaxKind, этот разработчик сразу же пришел ко мне в офис и пожаловался: «int — это деталь реализации, меня должны были заставить сделать приведение!».Спустя годы, во время очередной ревизии API, мы полностью удалили свойства (
Property Kind As SyntaxKind), которые указывали на специфичный для языка тип, и все API начали возвращать Integer. Весь код C# сломался, а весь код VB продолжил работать как ни в чем не бывало.Чуть позже мы решили переименовать это свойство в
RawKind и добавить специфичные для языка методы расширения Kind(). Весь код C# сломался, потому что для вызова методов были необходимы круглые скобки, но так как в VB они не нужны, весь код VB снова продолжил работать как ни в чем не бывало.36. Проверка переполнения (overflow)/отрицательного переполнения (underflow) для целочисленной арифметики полностью контролируется средой компиляции (настройки проекта), но VB и C # используют разные значения по умолчанию; в VB проверка переполнения по умолчанию включена
Интегральные типы имеют диапазон, поэтому, например,
Byte может представлять значения от 0 до 255. Итак, что происходит, когда вы добавляете Byte 1 к Byte 255? Если проверка overflow/underflow отключена, значение прокручивается в 0. Если тип со знаком, он прокручивается до самого нижнего отрицательного числа (например, -128 для SByte). Это скорее всего указывает на ошибку в вашей программе. Если проверка overflow/underflow включена, бросается исключение. Чтобы понять, что я имею в виду, взгляните на этот безобидный цикл For.исходный код на GitHub
По умолчанию в VB этот цикл будет бросать исключение (поскольку последняя итерация цикла переходит за границу
Byte. Но с отключением проверки overflow он зацикливается, потому что после 255 i снова становится 0.Underflow — это противоположная ситуация, когда вычитание ниже минимального для типа значения приводит к максимальному значению.
Более распространенная ситуация для переполнения — это просто сложение двух чисел. Возьмите числа 130 и 150, оба как
Byte. Если вы их сложите, ответ будет 280, что не вписывается в Byte. Но ваш процессор воспринимает это не так. Вместо этого он сообщает, что ответ 24.Кстати, это никак не связано с преобразованиями. Сложение двух байтов дает байт; это просто способ работы двоичной математики. Хотя вы также можете получить переполнение, выполнив преобразование, например, при попытке преобразовать Long в Integer. Без проверки переполнения программа просто отсекает лишние биты и запихивает столько, сколько влезает в эту переменную.
В чем разница? Производительность. Проверка CLR на переполнение требует немного больше вычислительного времени по сравнению с вариантом без проверки, как и все прочие проверки безопасности. VB основан на философии, согласно которой продуктивность разработчиков важнее производительности вычислений, поэтому по умолчанию вам включили проверку безопасности. Команда разработчиков C# сегодня может принять другое решение по дефолтным настройкам проекта, но если учесть, что первые разработчики C# получились из разработчиков C/C++, эта группа людей, вероятно, потребовала бы, чтобы код не делал ничего лишнего, что могло бы стоить циклов процессора; это непростое философское различие.
Нюанс: даже если проверка overflow/underflow выключена, преобразование значений
PositiveInfinity, NegativeInfinity, NaN типов Single или Double в Decimal выбросит исключение, поскольку ни одно из этих значений не может быть в принципе представлено в Decimal.37. Преобразование чисел с плавающей запятой в целочисленные типы использует банковское округление (bankers rounding), а не усечение (truncating)
Eсли вы в VB преобразуете число 1.7 в целое число, результат будет 2. В C# результат будет 1. Я не могу ничего сказать про математические правила за пределами Америки, но я при переходе от действительного числа к целому инстинктивно округляю. И никто из тех, кого я знаю вне круга программистов, не считает, что ближайшим целым числом к 1.7 является 1.
На самом деле есть несколько способов округления, и тип округления, используемый в VB (и в методе Math.Round) по умолчанию называется банковским округлением или округлением статистиков. Его суть в том, что для числа посередине между двумя целыми числами VB округляет до ближайшего четного числа. Так 1,5 округляется до 2, а 4,5 округляется до 4. Что на самом деле работает не так, как нас учили в школе — меня учили округлять вверх от 0,5 (технически, округлять в сторону от нуля). Но, как следует из названия, банковское округление имеет преимущество в том, что при большом количестве вычислений вы делите при округлении пополам, а не всегда раздаете или всегда удерживаете деньги. Другими словами, на большом множестве это ограничивает искажение данных предельным статистическим отклонением.
Откуда различие? Округление интуитивнее и практичней, усечение быстрее. Если вы рассмотрите использовании VB в LOB-приложениях и особенно в таких приложениях, как макросы Excel, работающие на VBA, то простое отбрасывание цифр после запятой может вызвать… проблемы.
Я думаю, очевидно, что способ преобразования – это всегда вопрос неоднозначный и должен указываться явно, но вот если вам нужно выбрать единый…
38. Не является ошибкой преобразовывать NotInheritable классы в/из интерфейсов, которые они не реализуют на этапе компиляции
Вообще говоря, если вы проверяете NonInheritable-класс на реализацию интерфейса, вы можете понять во время компиляции, возможно ли такое преобразование, потому что вы знаете все интерфейсы этого типа и все его базовые типы. Если тип наследуемый, вы не можете быть уверенными, что такое преобразование невозможно, потому что тип объекта времени выполнения, на который указывает ссылка, может по факту иметь более производный тип, который реализует этот интерфейс. Однако есть исключение из-за COM interop, когда во время компиляции может быть не видно, что тип имеет какое-либо отношение к интерфейсу, но во время выполнения это будет так. По этой причине компилятор VB в таких случаях выдает предупреждение.
Почему? VB и COM росли вместе во времена, когда они были детьми в старом районе. Так что в дизайне языка есть несколько решений, в которых VB уделяет большое внимания вещам, которые существовали только в COM на момент релиза .NET 1.0.
39. Попытка распаковать (unbox) null в значимый тип приводит к значению типа по умолчанию, а не к NullReferenceException
Я полагаю, что технически это также верно для ссылочных типов, но да:
Почему? Потому что
CInt(Nothing) = 0, и язык стремится быть в какой-то степени последовательным независимо от того, типизировали ли вы свои переменные или нет. Это относится к любой структуре, а не только к встроенным значимым типам. См. обоснование в #25 для более подробной информации.40. Распаковка (unboxing) поддерживает преобразования примитивных типов
И в VB, и в C# вы можете конвертировать
Short в Integer, но что если вы попытаетесь конвертировать упакованный Short в Integer? В VB Short будет сначала распакован, а затем преобразован в Integer. В C# если вы вручную не распакуете short перед преобразованием в int, будет брошено InvalidCastException.Это относится ко всем внутренним преобразованиям, то есть упакованным числовым типам, преобразованиям между строками и числовыми типами, строками и датами (да, Decimal и Date — примитивные типы).
Почему? Опять же, чтобы обеспечить согласованное поведение, полностью ли строго типизирована ваша программа, типизирована как Object или находится в процессе рефакторинга от одного варианта к другому. Смотрите #39 выше.
41. Есть преобразования между String и Char
Stringпреобразуется вChar, представляющий ее первый символ.Charпреобразуется вStringединственным разумным способом.
Потому что никто, кроме меня, не помнит синтаксис символьного литерала в VB (да и не должен).
42. Есть преобразования между String и массивом Char
Stringпреобразуется в массивChar, состоящий из всех ее символов.- Массив
Charпреобразуется вString, состоящую из всех его элементов.
Для определенности: эти преобразования создают новые объекты, вы не получаете доступ к внутренней структуре
String.Забавная история: однажды я нашел (или, возможно, об этом сообщили, и я исследовал) breaking change между .NET 3.5 и 4.0, потому что между этими версиями команда .NET добавила модификатор
ParamArray ко второму параметру перегрузки String.Join, принимающему массив строк. Точные предпосылки потеряны во времени (вероятно, к лучшему), но, как я считаю, причина в том, что с модификатором ParamArray теперь можно конвертировать в строку массив Char, и передать ее как отдельный элемент в массив параметров. Веселая тема.43 и 44. Преобразования из String в числовые типы и типы дат поддерживают синтаксис литералов (как правило)
CInt("&HFF") = 255CInt("1e6") = 1_000_000CDate("#12/31/1999#") = #12/31/1999#
Это работает с префиксами основания и делает возможным очень удобный способ преобразования шестнадцатеричного (или восьмеричного) ввода в число:
CInt("&H" & input). К сожалению, эта симметрия деградирует на момент написания этой статьи, потому что среда выполнения VB не была обновлена для поддержки двоичного префикса &B или разделителя групп цифр 1_000, но я надеюсь, что это будет исправлено в следующей версии. Научная нотация работает, но без суффиксов типов, а преобразования даты также поддерживают стандартные форматы дат, поэтому формат JSON, используемый в ISO-8601, также работает: CDate("2012-03-19T07: 22Z") = #3/19/2012 02:22:00 AM#.Почему? Я не знаю другой причины кроме удобства. Но я бы очень хотел предложить также поддержку других распространенных форматов, которые сегодня практически повсеместны в сети, таких как #FF, U+FF, 0xFF. Я думаю, это могло бы сильно облегчить жизнь в некоторых типах приложений…
45. НЕТ преобразований между Char и целочисленными типами
ЧТО?!?!?
После прочтения обо всех этих дополнительных преобразованиях вы удивлены? В VB запрещаются преобразования между
Char и Integer:CInt("A"c)не компилируется.CChar(1)не компилируется.
Почему? Неясно, что должно произойти. Обычно VB в таких ситуациях использует прагматичный и/или интуитивный подход, но для выражения
CInt("1"с) я думаю, половина читателей ожидала бы число 1 (значение символа 1), а половина ожидала бы число 49 (код ASCII/UTF для символа 1). Вместо того, чтобы в половине случаев делать неправильный выбор, VB имеет специальные функции для преобразования символов в коды ASCII/Unicode и обратно, AscW и ChrW соответственно.Выражения
46. Nothing <> null
Литерал
Nothing в VB не означает null. Он означает «значение по умолчанию для типа, в качестве которого оно используется», и просто так сложилось, что для ссылочных типов значением по умолчанию является null. Различие имеет значение только при использовании в контексте, в котором:- Nothing принимает значимый тип, и…
- Из контекста непонятно, что он это делает.
Давайте рассмотрим несколько примеров, которые иллюстрируют, что это значит.
Первый, возможно немного странный, но я не думаю, что большинству людей взорвет мозг понимание, что эта программа напечатает «True»:
исходный код на GitHub
Причина достаточно проста: вы сравниваете
Integer (0) со значением по умолчанию его типа (тоже 0). Проблема возникает в VB2005/2008, когда вы добавляете nullable значимые типы. Посмотрите на этот пример:исходный код на GitHub
Понятно, как кто-то может предположить, что тип
i является Integer? (Nullable(Of Integer)). Но это не так, потому что Nothing получает тип из контекста, а единственный тип в этом контексте исходит от второго операнда, и это простой non-nullable Integer (технически Nothing никогда не имеет типа). Другой способ взглянуть на эту проблему — следующий пример:исходный код на GitHub
Опять же, здесь интуитивно кажется, что
Nothing добавляет подсказку «nullable» и что язык выберет перегрузку, которая принимает nullable, но он этого не делает (выбирает non-nullable, поскольку она «наиболее специфична»). Как минимум, можно предположить, что как и null в C#, выражение Nothingвообще не применимо к Integer, и что nullable-перегрузка будет выбрана методом исключения, но это опять-таки основано на неправильной мысли, что Nothing = null (Is null?).Нюанс: в C# 7.1 было добавлено новое выражение
default, которое соответствует Nothing в VB. Если вы перепишете все три примера выше на C#, используя default вместо null, вы получите точно такое же поведение.Что можно сделать по этому поводу? Имеется несколько предложений, но ни одно пока не победило:
- Показывать предупреждение каждый раз, когда
Nothingпреобразуется в значимый тип и это неnullвnullableзначимом типе. - Красиво разворачивать
Nothingв0,0.0,ChrW(0),False,#1/1/0001 12:00:00 AM#илиNew T(значение по умолчанию для любой структуры) каждый раз, когда его значение в рантайме будет одним из перечисленных выше. - Добавить новый синтаксис, означающий «Null, нет, правда!», вроде
NullилиNothing? - Добавить новый синтаксис в виде суффикса (?), который оборачивает значение в nullable, чтобы помочь вывести тип, например
If(False, 0?, Nothing) - Добавить nullable операторы преобразования для встроенных типов, чтобы было легче давать подсказки выводу типа, например,
If (False, CInt? (0), Nothing)
Хотелось бы услышать ваши мысли в комментариях и/или в Твиттере.
Итак, подведем итоги:
- Прежние времена — VB6 и VBA имеют «Nothing», «Null», «Empty» и «Missing», означающие разные вещи.
- 2002 — в VB.NET есть только
Nothing(значение по умолчанию в конкретном контексте), а в C# — толькоnull. - 2005 — C# добавляет
default(T)(значение по умолчанию типаT), потому что свежедобавленные дженерики создают ситуацию, когда вам нужно инициализировать значение, но вы не знаете, является ли оно ссылочным типом или значимым; VB не делает ничего, потому что этот сценарий уже закрытNothing. - 2017 — C# добавляет
default(значение по умолчанию в контексте), поскольку существует множество сценариев, в которых указаниеTизбыточно или невозможно
VB продолжает сопротивляться добавлению выражения
Null(или эквивалентного), потому что:- Синтаксис будет breaking change.
- Синтаксис не будет breaking change, но в зависимости от контекста будет означать разные вещи.
- Синтаксис будет слишком незаметный (например,
Nothing?); представьте, что нужно вслух поговорить оNothingиNothing?, чтобы что-то объяснить человеку. - Синтаксис может быть слишком уродливым (например,
Nothing?). - Сценарий выражения значения null уже закрыт
Nothing, и эта функция будет абсолютно избыточной большую часть времени. - Везде вся документация и все инструкции должны быть обновлены, чтобы рекомендовать использовать новый синтаксис, в основном объявляющий
Nothingустаревшим для большинства сценариев. NothingиNullпо-прежнему будут вести себя одинаково в рантайме в отношении позднего связывания, преобразований и т.д.- Это может быть как пушка в поножовщине.
Как-то так.
Оффтоп (но связанный)
Вот пример, очень похожий на второй выше, но без вывода типа:
исходный код на GitHub
Эта программа выводит на экран 0. Он ведет себя точно так же, как и второй пример, по той же причине, но иллюстрирует отдельную, хотя и связанную проблему. Интуитивно понятно, что
Dim i as Integer? = If(False, 1, Nothing) ведет себя так же, как Dim i As Integer? : If False Then i = 1 Else i = Nothing. В данном случае это не так, потому что условное выражение (If) не «пропускает» (flow through) информацию конечного типа к своим операндам. Оказывается, это ломает все выражения в VB, которые полагаются на то, что называется конечной (контекстной) типизацией (Nothing, AddressOf, массив литералов, лямбда-выражения и интерполированные строки) с проблемами, начиная от некомпилируемости вообще до тихого создания неправильных значений и до громкого выбрасывания исключений. Вот пример некомпилируемого варианта:исходный код на GitHub
Эта программа не будет компилироваться. Вместо этого она сообщает об ошибке в выражении
If, что она не может определить тип выражения, когда явно оба выражения AddressOf предназначены для получения делегатов Func(Of Integer, Integer, Integer).Здесь важно иметь в виду, что решение проблем с
Nothing не всегда означающим null (контринтуитивно), Nothing не указывающим на nullability (контринтуитивно) и If(,,) не обеспечивающим контекст для интуитивного поведения Nothing (и других выражений) (контринтуитивно) — это все отдельные проблемы, и решение одной НЕ решит другие.47. Скобки влияют не только на приоритет парсинга; они реклассифицируют переменные в значения
Эта программа выводит на консоль «3»:
исходный код на GitHub
Аналогичная программа на C# выдаст «-3». Причина в том, что в VB взятие переменной в скобки заставляет ее вести себя как значение — процесс, известный как реклассификация. В этот момент программа ведет себя так, как если бы вы написали
M(3), а не M(i), и никакой ссылки на переменную iне передается, так что она не может быть изменена. В C# взятие выражения в скобки (по любой причине) не сделает его значением вместо переменной, так что вызов M изменит исходную переменную.Почему? В VB всегда было такое поведение. На самом деле я только что открыл свою копию Quick Basic (Copyright 1985), и там поведение такое же. С учетом того, что передача по ссылкеиспользовалась по умолчанию до 2002 года, все это очевидно имеет смысл.
Нюанс №1: «Как подпрограмма получила круглые скобки» Пола Вика, заслуженного архитектора Visual Basic .NET.
Нюанс №2: Когда мы проектировали связанное дерево в компиляторах Roslyn (структуру данных, представляющую семантику программы (значение вещей) в отличие от синтаксиса (форма записи вещей)), это стало камнем преткновения для команды компиляторов: будут ли выражения в скобках представлены в связанном дереве. В C# круглые скобки являются почти полностью синтаксической конструкцией, используемой для контроля приоритета синтаксического анализа
((a + b) * c или a + (b * c)). Настолько, что оригинальный компилятор C#, написанный на C++, отбрасывал факт, что выражение было заключено в скобки, вместе с такими вещами, как пробелы и комментарии. Было несколько попыток согласования между языками: «Можем ли мы посмотреть и избавиться от них в VB?» или «Можем ли мы жить с ними в C#?» и в конечном итоге согласно source.roslyn.io результат — BoundParenthesized присутствует в компиляторе VB и отсутствует в компиляторе C#. Другими словами, языки здесь различаются, и мы просто должны это принять.
48. Me всегда классифицируется как значение — даже в структурах
В VB.NET вы не можете присваивать в
Me. Обычно это не вызывает удивления, но кто-то может подумать, что поскольку структуры — это просто набор значений, то допустимо присваивать в Me внутри конструктора или метода экземпляра типа Structure как упрощенную запись копирования. Однако это тоже запрещено и при передаче Me по ссылке будет просто передана копия. В C# допустимо присваивать в this внутри структуры, и вы можете передать this по ссылке внутри методов экземпляра структуры.49. Методы расширения доступны по простому имени
В VB, если для типа определен метод расширения и он находится в области видимости определения этого типа, то внутри определения этого типа вы можете вызвать этот метод по неквалифицированному имени:
исходный код на GitHub
В C# методы расширения ищутся только при явном указании получателя (то есть something.Extension). Так что, хотя точный перевод примера выше не будет компилироваться в C#, вы можете получить доступ к расширениям в текущем экземпляре, явно указав
this.Extension().Почему? Можно привести аргумент, что к обычным членам экземпляра можно получить доступ без явной их квалификации с помощью
'Me.', и, поскольку методы расширения ведут себя везде как члены экземпляра, логично, что они так ведут себя и в этом контексте. VB.NET придерживается этого аргумента. Предположительно есть и другие аргументы, и другие языки вольны их придерживаться.50. Импорт статиков не объединяет группы методов (Static imports will not merge method groups)
VB всегда поддерживал «статический импорт» (Java-термин, объединяющий модификатор C# с оператором VB). Это то, что позволяет мне написать
Imports System.Console вверху файла и использовать WriteLine() без квалифицирования в остальной части файла. В 2015 году C# также получил такую возможность. Однако в VB ситуация импорта двух типов с Shared-членами с одинаковыми именами, например System.Console и System.Diagnostics.Debug, оба из которых имеют методы WriteLine, всегда трактуется как неоднозначность. C# объединит группы методов и выполнит разрешение перегрузки, и если есть однозначный результат, то он и будет выбран.Почему? Я думаю, можно считать, что здесь VB мог бы быть умнее, как C# (особенно учитывая следующее отличие). Но также есть аргумент, что если два метода происходят из двух разных мест и вообще не имеют никакого отношения друг к другу (один не является методом расширения для типа, определяющего другой), то это… вводит в заблуждение, когда все варианты предлагаются под одним и тем же именем.
Более того, в VB есть множество случаев с таким же сценарием, когда VB выбирает более безопасный путь и сообщает о неоднозначности, например, два метода с одинаковым именем из несвязанных интерфейсов, два метода с одинаковым именем из разных модулей, два метода с разных уровней иерархии наследования, где один не является явной перегрузкой другого (отличие #6). VB здесь философски последователен. Кроме того, VB принял все эти решения в 2002 году.
51 и 52. Квалифицирование по неполному имени и умное разрешение имен (Partial-name qualification & Smart-name resolution)
Есть несколько способов трактовать пространства имен:
- С одной стороны, все пространства имен — это соседи в плоском списке и содержат только типы (но не другие пространства имен). Так что
SystemиSystem.Windows.Forms— это соседи, которые имеют по соглашению общий префикс, ноSystemне содержитSystem.WindowsиSystem.Windowsне содержитSystem.Windows.Forms. - С другой стороны, пространства имен похожи на папки, организованные в иерархию, и могут содержать другие пространства имен и типы. Так что
SystemсодержитWindows, аWindowsсодержитForm.
Первая модель, в частности, полезна для отображения пространств имен в графическом интерфейсе без глубокого вложения. Однако мне всегда была интуитивно ближе вторая. И VB с его директивой Imports следует второй модели, а
using в C# ведет себя согласно первой.Следовательно, если в VB я импортировал пространство имен
System, я могу получить доступ к любому пространству имен внутри System, не квалифицируя его с помощью System. Для меня это все равно, что указать относительный путь. Так что во всех моих примерах, где я квалифицирую ExtensionAttribute, я пишу <Runtime.CompilerServices.Extension> вместо <System.Runtime.CompilerServices.Extension>.В C# это не так.
using System не добавляет System.Threading в область видимости под простым именем Threading.Но получается даже лучше, потому что C# позволяет сценарий частичной квалификации аналогично относительному пути конкретно в случае, когда код определен в этом пространстве имен. То есть, если вы объявляете тип внутри
System, то внутри этого типа вы можете ссылаться на пространство имен System.Threading как Threading. И это последовательное поведение, потому что вы можете объявить пространство имен и тип, лексически содержащиеся в другом пространстве имен, и было бы странно, если поиск по имени внутри типа не нашел бы соседа.Но получается даже хуже, потому что, хотя и VB, и C# требуют, чтобы пространства имен всегда были полностью квалифицированы в инструкциях
Imports/директивах using уровня файла, C# позволяет вам иметь директиву using внутри объявления пространства имен, влияя на код внутри этого объявления в этом файле, и в таких директивах using пространства имен могут указываться с использованием простого имени.Появление квантовых пространств имен (Quantum Namespaces) (неофициальное название)
Но подождите, это еще не все! Модель VB удобна, но это удобство сопряжено с риском. Ведь что происходит, если
System содержит пространство имен ComponentModel и System.Windows.Formsсодержит пространство имен ComponentModel? Смысл ComponentModel становится неоднозначным. И иногда получается, что вы можете просто писать в коде ComponentModel.PropertyChangedEventArgs, и все будет хорошо (я смутно припоминаю, что более ранние версии дизайнера так делали в сгенерированном коде). Но тогда вы импортируете System.Windows.Forms (или, может быть, просто добавите ссылку на сборку, которая объявляет подпространство имен с таким именем в том, которое вы импортировали), весь ваш код сломается с ошибками неоднозначности (ambiguity errors).Поэтому в VB2015 мы добавили интеллектуальное разрешение имен (Smart Name Resolution), при котором если вы импортировали
System и System.Windows.Forms и пишете ComponentModel, то по аналогии с котом Шредингера создается квантовая суперпозиция из обеих реальностей, где вы ссылаетесь на System.ComponentModel и где вы ссылаетесь на System.Windows.Forms.ComponentModel, пока вы не введете другой идентификатор. Если этот идентификатор представляет собой дочернее пространство имен в обеих реальностях, волна продолжится до тех пор, пока не встретится идентификатор, однозначно указывающий на тип, существующий только в одной временнОй вселенной. В этот момент волна схлопывается, и оказывается, что кот всегда была мертв, т.е. ComponentModel.PropertyChangedEventArgs должно означатьSystem.ComponentModel.PropertyChangedEventArgs, потому что System.Windows.Forms.ComponentModel.PropertyChangedEventArgs не существует. Это позволяет избежать многих неоднозначностей, которые могут возникнуть просто при импорте нового пространства имен.Но это не решает проблему добавления ссылки, которая приносит новое пространство имен верхнего уровня
Windows в область видимости, потому что пространства имен верхнего уровня (абсолютные пути) всегда побеждают определенные частично (относительные пути) по различным причинам (включая производительность). Поэтому использование WinForms/WPF и UWP в одном проекте все еще может быть болезненным.53. Методы Add инициализатора коллекции могут быть методами расширения
Как упомянуто в #33, когда VB что-то ищет, он обычно рассматривает и методы расширения. Сценарий, когда вам это может понадобиться, — использование краткого синтаксиса инициализатора для коллекций сложных объектов, например:
исходный код на GitHub
Изначально C# не рассматривал методы расширения в этом контексте, но когда мы заново реализовали инициализаторы коллекций в компиляторе Roslyn C#, они стали их учитывать. Это был баг, который мы решили не исправлять (а не фича, которую мы решили добавить), так что это различие актуально только до VS2015.
54. Создание массива использует верхнюю границу, а не размер
На удивление редко упоминается, но при инициализации массива в VB с синтаксисом
Dim buffer(expression) As Byte или Dim buffer = New Byte(expression) {} размер массива всегда равен expression + 1.Это всегда было так в языках Microsoft BASIC, со времен появления инструкции
DIM (означающей dimension — размер). Что, я полагаю, объясняет, почему это так работает: размер массива от 0 до expression. В предыдущих версиях языков Microsoft BASIC можно было изменить нижнюю границу массивов по умолчанию на 1 (и можно было объявить массив с произвольной нижней границей, например 1984), в этом случае верхняя граница совпадала с длиной (я обычно так делал), но эта возможность исчезла в 2002 году.Но если копнуть глубже, я слышал про модное когда-то веяние в языковом проектировании делать синтаксис объявления моделирующим синтаксис использования, что объясняет, почему массивы в VB объявляются с их верхней границей, почему в BASIC и в C границы массивов указываются на переменной, а не на типе, синтаксис указателей в C, почему типы находятся слева в C-подобных языках. Подумайте об этом, любое использование
buffer(10) будет использовать значение от 0 до 10, а не до 9!
55. Литералы массива VB ср-я магия не то же самое, что неявно типизированные выражения создания массива в C#
Хотя эти две функции часто используются в одних и тех же сценариях, они не одинаковы. Основное отличие состоит в том, что литералы массива VB по своей природе не типизированы (как лямбды) и получают тип из контекста, а в отсутствие контекста — из выражений своих элементов. Спецификация хорошо это иллюстрирует:
CType({1, 2, 3}, Short())не означаетCType(New Integer() {1, 2, 3}, Short ()), поскольку невозможно преобразовать массивIntegerв массивShort.CType({1, 2, 3}, Short())переклассифицирует литерал массива вNew Short() {1, 2, 3}. Ложки нет.
Это на самом деле довольно круто, потому что означает, что с литералом массива VB могут происходить вещи, которые невозможны с неявно типизированным массивом в C#. Например, передача пустого:
Dim empty As Integer() = {}
Создание массива нетипизированных выражений:
Dim array As Predicate(Of Char)() = {AddressOf Char.IsUpper, AddressOf Char.IsLower, AddressOf Char.IsWhitespace}
Выполнение поэлементных преобразований (внутренних или пользовательских):
Dim byteOrderMark As Byte() = {&HEF, &HBB, &HBF} 'Не нужны байтовые литералы.
И так как целевой тип выводится не только из массивов, но также из
IList(Of T), IReadOnlyList(Of T), ICollection(Of T), IReadOnlyCollection(Of T) и IEnumerable(Of T), вы можете очень лаконично передать переменное число аргументов в метод, принимающий один из этих типов, что делает ненужным ParamArray IEnumerable.Почему? До написания этого документа я думал, что это различие в основном сводится к дополнительным усилиям со стороны VB. Но теперь я считаю, что всё гораздо проще. До появления вывода локальных типов в 2008 году VB и C# позволяли вам инициализировать объявление массива с помощью синтаксиса «множества» {}, но вы не могли использовать этот синтаксис где-либо еще в языке (за исключением, я думаю, атрибутов). То, что мы сейчас считаем литералами массива, на самом деле является просто обобщением того, что этот синтаксис может сделать с любым контекстным выражением + несколько других тонкостей, таких как вывод из вышеупомянутых обобщенных интерфейсов. Что весьма элегантно.
56. Поля анонимного типа могут быть И являются изменяемыми
Это не затрагивает поля анонимного типа, созданные неявно с помощью LINQ. Но созданные вами могут быть изменяемыми или неизменяемыми, все зависит от вас.
Подробности о том, почему и как, здесь.
57. Ни CType, ни DirectCast не являются в точности приведением типов в C#
Нет точного соответствия между операторами приведения/преобразования между VB и C#.
VB
CType:- Поддерживает пользовательские преобразования;
- Поддерживает ссылочные преобразования (базового класса в производный);
- Поддерживает внутренние преобразования, например,
LongвInteger(см. раздел «Преобразования»); - Распаковывает (unboxes) сложные значимые типы напрямую;
- НЕ распаковывает примитивные типы напрямую;
- НЕ поддерживает динамические преобразования (используйте функцию
CTypeDynamic).
VB
DirectCast:- НЕ поддерживает пользовательские преобразования;
- Поддерживает ссылочные преобразования;
- НЕ поддерживает внутренние преобразования (не может преобразовать
Integer в Byte); - Распаковывает сложные значимые типы напрямую;
- Распаковывает примитивные типы напрямую (отсюда и название);
- НЕ поддерживает динамические преобразования.
Приведение в C# —
(Type)expression:- Поддерживает пользовательские преобразования;
- Поддерживает ссылочные преобразования;
- Поддерживает внутренние преобразования;
- Распаковывает сложные значимые типы напрямую;
- Распаковывает примитивные типы напрямую;
- Поддерживает динамические преобразования.
Из первых двух
CType ближе всего к приведению в C# в том смысле, что его можно использовать в более широком наборе сценариев. На самом деле, с точки зрения языка это оператор преобразования. Но VB и C# разрешают и запрещают разные преобразования, имеют разную семантику для одних и тех же преобразований и в некоторых случаях генерируют разный IL для этих преобразований. Так что нет способа получить точно такой же набор преобразований, как в C#, с точно такой же семантикой и точно таким же кодом, сгенерированным во всех случаях с помощью одного и того же оператора. И не должно быть.В действительности, все могут использовать
CType, за исключением динамических преобразований (преобразований, которые ищут пользовательский оператор преобразования во время выполнения). CType поддерживает все сценарии, которые поддерживает DirectCast, и даже больше. И всегда, когда они оба могут быть использованы, они будут генерировать один и тот же IL за одним исключением: при преобразовании из Object (или ValueType) в примитивный тип вместо генерации инструкции CLR «unbox» компилятор генерирует вызов функции VB-рантайма, которая завершится успешно, если тип объекта является целевым типом ИЛИ если значение объекта может быть преобразовано в этот тип (например, расширением Short до Integer). Это означает, что он будет чаще завершаться успехом, чем в C#. Но в этом случае поддерживаются только внутренние преобразования между примитивными типами. В чрезвычайно узком наборе сценариев это может иметь значение, но в подавляющем большинстве случаев нет.Почему? Языки поддерживают различные преобразования. Операторы преобразования должны поддерживать преобразования, которые поддерживают языки, а не преобразования, которые поддерживают другие языки, если нет особой причины.
58. Приоритет некоторых «эквивалентных» операторов не обязательно совпадает
Полные таблицы приоритетов операторов смотрите в спецификациях, но они не одинаковы для разных языков, поэтому
5 Mod 2 * 3 вычисляется как 5 в VB, а «эквивалентное» выражение в C# 5 % 2 * 3вычисляется как 3.Приоритет операторов является, вероятно, самой старой частью любой семьи языков. Я заметил это только когда рассмотрел влияние операторов, которые существуют только в одном языке (например, целочисленное деление (\) в VB), на операторы после него, которые в противном случае могли бы быть на том же уровне, но похоже различия гораздо более распространены. Вы предупреждены!
59. Конкатенация строк отличается; + и & отличаются в контексте конкатенации строк; + в VB <> + в C#
Давайте просто поговорим о том, как + (сложение) и & (конкатенация) в VB отличаются друг от друга и от + в C#.
Между
String и примитивными типами:VB
- “1” + 1 = 2.0
- “1” & 1 = “11”
C#
- «1» + 1 == «11»
Между строкой и типами, которые не перегружают + и &
VB
- “obj: “ + AppDomain.CurrentDomain ‘ Error: + not defined for String and AppDomain.
- ”obj: “ & AppDomain.CurrentDomain ‘ Error: & not defined for String and AppDomain.
- ”obj: “ + CObj(AppDomain.CurrentDomain) ‘ Exception, no + operator found.
- ”obj: “ & CObj(AppDomain.CurrentDomain) ‘ Exception, no & operator found.
C#
- «obj: » + AppDomain.CurrentDomain == «obj: » + AppDomain.CurrentDomain.ToString()
- «obj: » + (object)AppDomain.CurrentDomain == «obj: » + AppDomain.CurrentDomain.ToString()
- «obj: » + (dynamic)AppDomain.CurrentDomain == «obj: » + AppDomain.CurrentDomain.ToString()
Между числовыми типами:
VB
- 1 + 1 = 2
- 1 & 1 = “11”
C#
- 1 + 1 == 2
Между типами String и Enum:
VB
- “Today: ” + DayOfWeek.Monday ‘ Exception: String «Today: » cannot be converted to Double.
- “Today: ” & DayOfWeek.Monday = “Today: 1”
- “Today: ” & DayOfWeek.Monday.ToString() = “Today: Monday”
C#
- «Today: » + DayOfWeek.Monday == «Today: Monday»
Больная мозоль: мне очень не нравится, что + в принципе допускается использовать для конкатенации строк в VB, он остался из-за обратной совместимости. + всегда объединяет строки, но его текущее поведение больше похоже на баг, чем на что-то еще. Почему? Потому что:
- “10” — “1” = 9.0,
- “5” * “5” = 25.0,
- “1” << “3” = 8, и
- “1” + 1 = 2.0, но
- “1” + “1” = “11”
Любой другой арифметический оператор преобразует строки в числа. Неконсистентность плюса — это баг в дизайне.
Итог: не используйте +, потому что он выглядит как в других языках. Чтобы получить нужное вам поведение, используйте &, потому что этот выделенный оператор существует, чтобы однозначно указать намерение (конкатенация, а не сложение). Кроме того, будьте осторожны при конкатенации значений перечисления, они ведут себя в этом контексте как их числовые значения.
60. Деление работает адекватно: 3 / 2 = 1,5
Время от времени я провожу эксперимент — подхожу к случайному человеку и спрашиваю его: «Сколько будет три поделить на два?». Большинство людей говорят «полтора». Только самые идеологизированные из нас бросают на меня взгляд и говорят: «Это зависит. Какие типы у тройки и двойки?»
В этом и состоит всё различие между VB и C#.
Если вам нужно поведение в стиле C, которое, я полагаю, является ответом на вопрос «Сколько раз 5 целиком входит в 9?», используйте оператор целочисленного деления \. Еще один аргумент, я полагаю, заключается в том, что деление замкнуто на множестве целых чисел, за исключением деления на 0 (что имело бы значение, если бы когда-нибудь возник интерфейс
INumeric).
61. ^ не совсем Math.Pow
То есть это не просто псевдоним для
Math.Pow. Это перегружаемый оператор, который должен быть явно вынесен из области примитивных типов. Меня огорчает, как часто пользовательские (custom) числовые типы не поддерживают его (я про тебя, System.Numerics.BigInteger).Нюанс: F# также имеет перегружаемый оператор возведения в степень **, но при перегрузке операторы VB и F# генерируют разные имена:
op_Exponent и op_Exponentiation соответственно. Хотя F# на самом деле ищет метод Pow по типам операндов. То есть эти языки плохо взаимодействуют друг с другом. Печальный факт, который я хотел бы однажды увидеть исправленным.62. Операторы =/<> никогда не являются равенством/неравенством ссылок
В C# ‘==’ иногда использует (перегруженный) оператор равенства, иногда языковое равенство, а иногда и равенство ссылок (если типы операндов не перегружают равенство и являются объектом или интерфейсом). В VB этот оператор никогда не будет означать равенство ссылок. VB имеет отдельные операторы (
Is/IsNot) для равенства ссылок.Время историй: в какой-то момент в истории Roslyn у нас была иерархия классов, которая перегружала равенство по значению. На самом деле у нас было две такие иерархии. Однажды мы решили абстрагироваться от обеих с помощью иерархии интерфейсов. Весь код VB как положено сломался при переходе на использование интерфейсов, потому что = перестал быть валидным, но на стороне C# образовался баг, потому что большая часть кода, которая ранее использовала перегруженное равенство по значению, молча начала использовать более строгое требование равенства ссылок.
63. Операторы =/<> для строк различаются (и любые другие операторы отношения в данном контексте)
Равенство строк в VB отличается в нескольких аспектах.
Во-первых, используется ли двоичное сравнение строк (чувствительное к регистру) или культурно-зависимое (нечувствительное к регистру), зависит от того, выставлено ли на уровне файла или проекта
Option Compare Binary или Option Compare Text. Option Compare Binary, кстати, является значением по умолчанию для всех проектов в VS.Эта настройка регулирует все явные и неявные сравнения строк (но не сравнения символов), которые происходят в языке, но не затрагивает большинство вызовов API. То есть:
- Равенство/неравенство: “A” = “a”/“A” <> “a”
- Отношение: “A” > “a”
- Операторы
Select Case: Select Case “A” : Case “a”
Но не:
- Вызовы
Equals: “A”.Equals(“a”) - Вызовы
Contains: ”A”.Contains(“a”) - Оператор запросов
Distinct: From s In {“A”, “a”} Distinct
Но есть еще одно, гораздо более существенное отличие, которое может вас удивить: в языке VB нулевые и пустые строки считаются равными. Таким образом, независимо от настройки
Option Compare, эта программа выведет «Empty».исходный код на GitHub
Так что технически s = "" в VB — это сокращение для
String.IsNullOrEmpty(s).Говоря практически, это различие не вводит людей в заблуждение так уж часто, как вы могли бы подумать, поскольку операции, которые можно выполнять над нулевой и пустой строками, практически одинаковы. Вы никогда не вызовете члены пустой строки, потому что заранее знаете все ответы, а конкатенация рассматривает нулевые строки как пустые.
Почему? Я считаю
Option Compare Text настройкой для обратной совместимости, но я понимаю, почему она вообще появилась. Существует множество ситуаций, когда вы хотите, чтобы при сравнении строк не учитывался регистр.На самом деле, в большинстве случаев, когда я использую строки, я хочу, чтобы они не учитывали регистр.
По сути, во всех случаях, кроме паролей и ключей шифрования. Я не хочу, чтобы мое ленивое нежелание печатать буквально сказывалось на моих результатах. Да, я тот монстр, который использует сортировку (collation) без учета регистра в SQL Server, потому что я ценю свою продуктивность. И если учесть, что история VB включает в себя не только VB6, но и VBA для продуктов Office, таких как Excel и Access, и VBScript для Windows, и тот веб-браузер, который когда-то… ни у кого не было времени для учета регистра. Тем не менее, я принимаю, что .NET API в общем чувствительно к регистру, и не использую Option Compare Text, потому что она влияет только на уровне языка. Если бы была настройка, которая влияла бы на все .NET API, я бы врубил эту заразу и никогда больше к этому не возвращался.
Что касается null, рассматриваемого как пустая строка, у меня есть теория. В VB6 не было нулевых строк. Значение по умолчанию для
String было "". Таким образом, VB и его среда выполнения философски трактует значение по умолчанию для String как пустую строку. На самом деле это одно из главных преимуществ использования строковых функций VB, таких как Left и Mid, вместо методов String. Функции рантайма также обрабатывают null как пустую строку. Так что Len(CStr(Nothing)) = 0и Left(CStr(Nothing), 5) = "", а CStr(Nothing).Length или CStr(Nothing).Trim() просто упадет.К счастью, теперь вы можете получить такую же продуктивность с помощью оператора
?. (по крайней мере в части не выбрасывания исключений).Почему это важно:
Для меня главная проблема в том, что это различие присутствует везде, где в языке сравниваются два строковых значения, то есть любое сравнение строк в любом выражении. Включая выражения запросов! Способ сравнения строк VB заключается в том, что каждый раз, когда вы печатаете
"String A" = "String B", это превращается в вызов Microsoft.VisualBasic.CompilerServices.Operators.CompareString, и когда сравнение строк в выражении запроса или лямбда-выражении преобразуется в дерево выражений, оно отображается в дереве не как проверка на равенство, а как вызов этой функции. И неизменно каждый новый LINQ-провайдер генерирует исключение при обнаружении этого узла. Они просто не ожидают такого паттерна, потому что их библиотеки не были протестированы с VB (или не были протестированы достаточно хорошо). Это обычно означает, что поддержка этой библиотеки откладывается до тех пор, пока кто-то не сможет объяснить им, как распознать этот паттерн. Это произошло с LINQ-to-SQL, LINQ-to-Entities и некоторыми другими, с которыми я столкнулся во время работы в Microsoft. Все выглядит отлично, пока разработчик VB не сравнит две строки, затем БУМ!Так что помимо того, что семантика сравнения строк немного отличается от C#, это создает реальные проблемы для пользователей VB, использующих LINQ с новыми провайдерами. Варианты исправления: 1) изменить способ, которым VB генерирует деревья выражений, на явную ложь, или 2) изменить способ, которым VB генерирует равенство, с использованием паттерна, который будет проще распознать LINQ-провайдерам. Мне нравится последний, хотя он требует доработки рантайма VB (вероятно).
Нюанс: обратите внимание, что я сказал «большинство вызовов API». Потому что
Option Compare на самом деле влияет на вызовы строковых функций среды выполнения VB, таких как InStr.Replace и других членов модуля Microsoft.VisualBasic.Strings. Вы спросите, как настройка компиляции влияет на работу уже скомпилированной библиотечной функции?Ну, вы знаете, как компилятор может передать текущее имя файла или номер строки в качестве значения для некоторых необязательных параметров, если они правильно оформлены? Оказывается, до того, как эта функция была добавлена, та же схема была использована для строковых функций: компилятор передает значение, указывающее настройку в этой точке программы, через необязательный параметр.
64. Nullable значимые типы используют трехзначную логику (распространяют null в операторах отношения)
VB и C# по-разному обрабатывают nullable. В частности, в области распространения нуля (null-propagation).
Если вы много работаете с SQL, вы, вероятно, очень хорошо знакомы с распространением null. Вкратце это идея, что если взять некий оператор (например, +), и если один или несколько его операндов равен null, то результат всей операции тоже null. Это аналогично оператору
"?.": если в выражении obj?.Property obj равен null, то все выражение в результате выдает null, а не исключение.При использовании nullable значимых типов с унарными и бинарными операторами, и VB, и C# распространяют нули. Но они ведут себя по-разному в ключевой области: операторы отношения.
В VB, конкретно в случае с nullable значимыми типами, если любой из операндов равен null, все выражение имеет значение null за двумя исключениями. Так что 1 + null будет null и null + null будет null. Но это относится не только к арифметическим операциям, но и к операторам отношения (например, = и <>) и здесь кроется различие с C#:
- Все операторы отношения VB, кроме
Is/IsNot, возвращаютBoolean? - Все операторы отношения C# (==, !=, >, <, >=, <=) возвращают
boolвместоbool?
В VB (опять же конкретно для nullable значимых типов) сравнение null с любым другим значением дает null. То есть вместо обычного
Boolean оператор = возвращает Boolean?, который может принимать значения True, False или null. Это называется трехзначная логика. В C# результат сравнения всегда non-nullable bool, что соответственно является двузначной логикой.Обратите внимание, что я сказал любое значение. Это включает в себя собственно null. Так что в VB NULL = NULL — это NULL, а не TRUE.
Итак, пара забавных последствий соответствующих вариантов дизайна:

Это сломало мой мозг. Null не больше, чем он сам, но равен самому себе, и при этом не больше или равен себе в C#.
И в этом суть проблемы. Если в C# использовать модель VB, самый естественный способ задать вопрос «Равно ли это значение null?» в C#
(if (value == null)) будет каждый раз падать. В VB такой проблемы нет, потому что VB имеет отдельные операторы для равенства по значению (=/<>) и равенства по ссылке (Is/IsNot), поэтому идиоматичный способ проверки на нулевое значение в VB Is Nothing возвращает обычный non-nullable Boolean.Ранее я упоминал исключение из правила, согласно которому в VB все выражение равно null, если одни из операндов null. Это исключение касается операторов
And/AndAlso и Or/OrElse.Когда операнды имеют тип
Integer? (или другой интегральный), и VB, и C# распространяют null, как и следовало ожидать:- 1 AND NULL будет NULL
- 1 OR NULL будет NULL
Когда операнды имеют тип
Boolean?, в VB все сложнее.- FALSE AND NULL будет FALSE
- TRUE OR NULL будет TRUE
- TRUE AND NULL будет NULL
- FALSE OR NULL будет NULL
Другими словами, если результат
True/False может быть однозначно вычислен на основании одного операнда, результатом будет это значение, даже если другой операнд будет null. Это также означает, что короткое замыкание логических операторов AndAlso и OrElse работает как положено.В C# не разрешено применять логические операторы с коротким замыканием (&&/||) и без (&/|) к операндам
nullable boolean (bool?). Что не так проблематично, как я сначала подумал, потому что все операторы отношения генерируют non-nullable boolean и у nullable boolean операнда в любом случае мало шансов пробраться в выражение.Почему это имеет значение?
Обычно поведение VB удивляет только, когда кто-то пишет такой код:
исходный код на GitHub
Вы, вероятно, удивитесь, узнав, что эта программа выводит «EndDate change» три раза вместо двух. Помните, я сказал, что в VB null не равен самому себе? Поскольку он никогда не равен себе, когда сеттер свойства
EndDate проверяет, совпадает ли новое значение со старым значением, проверка не проходит во второй раз, когда код присваивает свойству значение Nothing.В этот момент разработчик VB обычно говорит: «Хорошо, я понял, как это работает. Я инвертирую это»:
Но так тоже не работает! На самом деле теперь в коде событие вообще не будет генерироваться. Вместо этого оно будет генерироваться, только если значение меняется с одного non-nullable значения на другое. Потому что нуль ни равен, ни неравен самому себе. Чтобы исправить ошибку, нужно написать так:
Откуда это различие и как лучше?
Я упомянул, почему команда C# решила пойти по пути их дизайна, и что эти проблемы вообще не относятся к VB. Размышляя о нулевых значениях (и в nullable значимых типах, и в ссылочных типах), я часто вижу конфликт между двумя понятиями о том, что представляет собой null.
Один из способов взглянуть на null — это в значении «ничто» или «не существует». Именно это обычно имеется в виду для ссылочных типов.
В других же случаях null означает «не определено» или «неизвестно». Зачастую это то, что подразумевается под необязательными параметрами, которые не были предоставлены: не то чтобы вызывающая сторона предлагает вам не использовать comparer, но ее устраивает, если вы используете comparer по умолчанию. И если вы посмотрите на базу кода Roslyn, то на самом деле есть тип с именем
Optional(Of T), который используется для описания этого понятия для ссылочных типов, потому что в противном случае невозможно отличить значения, которые должны быть равны null, от значений, которые просто не были предоставлены.И если вы используете последнюю интерпретацию, NULL как «неизвестное значение», то вся трехзначная логика в VB обретает смысл:
- Если я спрошу вас, «три больше, чем неизвестное значение?» вы можете ответить только «я не знаю».
- Аналогично: «У меня есть две коробки с неизвестными предметами, это одни и те же предметы?» «я не знаю».
И, вероятно, именно поэтому такая интерпретация используется по умолчанию в SQL-базах данных. По умолчанию, если вы попытаетесь сравнить NULL в SQL с любым значением, в ответ вы получите NULL. И это особенно актуально в работе с данными. Каждый, кто читает сейчас этот пост, будет иметь NULL в колонке Дата смерти. Это не означает, что мы все умрем в один день. Если несколько человек заполняют форму, большинство не будет заполнять свое отчество, хотя могут (это необязательно). Это не означает, что все эти люди имеют одинаковое отчество, хотя некоторые законно не имеют отчества и вы можете сказать, что отчество равно пустой строке, но вы понимаете, как значение NULL открыто для интерпретации, особенно в базах данных SQL (с исключениями).
Что возвращает нас к VB. Какой был самый крутой сценарий для nullable значимых типов в 2008 году, когда в VB была добавлена их полная всеобщая поддержка?
LINQ to SQL
Модель VB обеспечивает согласованность между базой данных, из которой, вероятно, поступают эти типы, и языком, а также между сравнениями, когда они возникают в LINQ-запросе и когда выполняются на сервере. Для меня это крайне убедительно!
Но есть подвох. В SQL Server, по крайней мере, есть опция SET ANSI_NULLS OFF, которая заставляет SQL-выражения вести себя скорее как в C#, так что вы можете написать
WHERE Column = NULL. И, признаюсь, в прошлом я обычно выставлял ее в OFF (вместе с выставлением сортировки базы без учета регистра). Так что я обратился к команде SQL Server (несколько лет назад) за помощью. Я спросил: «В чем смысл этой опции? Я использую ее. Верный ли это путь, и должны ли мы добавить что-то вроде Option ANSI_NULLS Off в VB.NET?». Их ответ в целом отражен в документации к опции:
Вкратце, эта опция нужна для обратной совместимости, вполне возможно исчезнет в будущем, и они хотели бы, чтобы все люди, использующие SQL Server, адаптировались к нынешнему подходу VB.
Как-то так.
65. Перегруженные операторы не всегда соответствуют 1:1
Есть случаи, когда VB поддерживает два представления оператора, который в других языках был бы единым, например, обычное и целочисленное деление. В этих случаях перегрузка оператора в VB может по-тихому перегружать другие операторы, используемые в других языках.
Аналогично, существуют случаи, когда другие языки перегружают определенные операторы по отдельности, например, логическое и побитовое отрицание или знаковое и беззнаковое побитовое смещение. В этих случаях VB может распознавать такие перегрузки, определенные в других языках, если они являются единственным доступным вариантом, а в тех случаях, когда доступны оба варианта, VB может игнорировать один вариант полностью.
Раздел 9.8.4 спецификации является исчерпывающим списком этих соответствий.
66. Function() a = b отличается от () => a = b
Я видел это несколько раз в конвертированном коде. Легко привыкнуть к мысли, что синтаксис
() => expression в C# всегда соответствует синтаксису Function() expression в VB. Однако лямбда Function() предназначена только для лямбда-выражений, которые что-то возвращают, что не так для присваивания в VB. Использование этого синтаксиса с телом вида a = b всегда будет производить делегат, который сравнивает a и b (возвращает Boolean), а не присваивает b в а. Однако из-за сокращения делегатов (delegate relaxation) VB эта лямбда все еще может безопасно (и по-тихому) передаваться в Sub-делегат (который не возвращает значение). В таком случае код просто молча ничего не делает. Правильный перевод () => a = b из C# в VB — это Sub() a = b. Этот код — это лямбда-инструкция, которая корректно содержит инструкцию присваивания и может быть использована для его побочных эффектов.Что обозначает оператор =, сравнение или присваивание, всегда определялось контекстом. В контексте инструкции (таком как
Sub-лямбда) он означает присваивание, в контексте выражения (таком как Function-лямбда) он означает сравнение.
67. Лямбда Async Function никогда не будет трактоваться как лямбда async void
В C# при написании
async лямбда-выражения, тело которого не возвращает значение, синтаксически неоднозначно, должна лямда возвращать Task или void, поэтому в разрешении перегрузок есть правило использовать вариант, возвращающий Task, если таковой имеется.В VB.NET такой неоднозначности нет, т.к. возвращающая
void Async лямбда использует синтаксис Async Sub, а возвращающая Task или Task(Of T) — использует синтаксис Async Function. Тем не менее, есть другая ситуация, которая может возникнуть в VB, когда упрощение (relaxing) Task Asyncлямбды в void делегат происходит за счет отбрасывания ее возвращаемого значения. Эта лямбда небудет вести себя как Async Sub, так что было добавлено предупреждение для случая, когда происходит такое упрощение.68. Запросы реальны (реальнее) в VB
Чтобы проиллюстрировать мой сенсационный заголовок, посмотрите на этот пример в VB:
исходный код на GitHub
По двум причинам он не будет компилироваться в VB, но будет в C#. Во-первых, тип
Foo не имеет метода Select, и поэтому он не может быть использован для запросов, так что не разрешается даже использовать на нем оператор Where. Но если вы раскомментируете определение Select, чтобы устранить эту ошибку, теперь не скомпилируется последний оператор Select, потому что Integer не может быть использован для запросов. Однако в C# трансляция сделана синтаксически таким образом, что весь запрос сводится к простому вызову .Where (последний Select отбрасывается). Поскольку она не использует все написанные конструкции запроса, она не выдает ошибок, когда паттерн поломан.Эта разница проявляется только в языковом дизайне или при попытке представить LINQ в API. Но способ, которым разработаны запросы в VB и C#, различен. В частности, запросы C# смоделированы на идее, что они являются всего лишь «синтаксическим преобразованием», что означает, что спецификация языка определяет их с точки зрения трансляции синтаксиса запроса в другой синтаксис, и весь семантический анализ происходит ПОСЛЕ того, как перевод закончен. В каком-то смысле это означает, что язык «отстранен» от того, что вещи могут значить посередине, и не предполагает гарантий относительно чего-либо.
С другой стороны, в VB язык тщательно описывает операторы запросов с достаточно строгой семантикой и может требовать, чтобы объекты придерживались определенных ограничений на промежуточных этапах, которые C# применил бы только после окончательного преобразования или вообще не применил, если трансляция их не требует.
Примеры вопросов, которыми нам пришлось задаться в Roslyn, включают: «Существуют ли переменные диапазона (range variables)?» и «Есть ли типы у переменных диапазона?». Ответ несколько различается в зависимости от рассматриваемого языка. Например, в VB вы можете явно задать типы переменных, объявленных в операторе запроса
Let, а в C# — нет. Но позвольте мне привести пример программы, эквивалент которой не скомпилируется ни в одной версии VB, но компилируется в C# 2012 несмотря на то, что она БЕЗУМНАЯ:исходный код на GitHub
Вы спросите, почему эта программа — безумие? Когда объявляется переменная X, ее тип —
string. Затем инструкция let объявляет новую переменную диапазона Y, которая также имеет тип string. Но нижележащий оператор запроса создает не последовательность анонимных типов, он фактически создает последовательность типов Point, который просто имеет свойства X и Y с теми же именами, что и наши переменные диапазона, но оба они типа int и совершенно не связаны с X и Y, «объявленными» в запросе. Так что когда вы ссылаетесь на переменную Y в инструкции select, она имеет тип int и члены int`а, и просто… компилируется.Вот что я имею в виду, когда говорю «Существуют ли переменные диапазона и имеют ли они типы?». До VS2015 в C# можно утверждать, что ответ «нет». Тем не менее, в Roslyn мы на самом деле немного ужесточили правила в C#, и эта программа больше не будет компилироваться. Размышления над этими двумя примерами принесли мне достаточно головной боли, так что какие бы ни были еще чудовищные примеры (а я уверен, что такие есть), пусть их плодит чей-нибудь другой мозг.
Почему? Это компромисс между простотой и элегантностью описания функции в спецификации и для пользователей и ее реализацией в виде простого синтаксического преобразования, а также спецификой опыта, который вы хотите создать, и всей связанной с этим работой. Не могу сказать, что есть правильный и неправильный подход для любой ситуации, команды разработчиков VB и C# и сами языки просто имеют здесь разные прецеденты и принципы.
69 и 70. Оператор As в запросе From не всегда вызывает cast; в качестве бонуса оператор 'As' может вызывать неявные пользовательские преобразования
(Потому что после предыдущего этот шокирует, но…)
Когда вы пишете
From x As Integer In y в VB, это не совсем то же самое, что и from int x in y в C#.Во-первых, в C# указание здесь типа всегда означает, что вы приводите (или конвертируете) исходную коллекцию. Будет сделан вызов
.Cast<T>(). В VB это может быть просто стилистический выбор, чтобы избежать вывода типа, и поэтому, если указанный тип является типом элемента коллекции, преобразование не выполняется.Во-вторых, вы не ограничены преобразованиями, которые могут выполняться статически методом
.Cast (известными как ссылочные преобразования). Вы можете использовать здесь любой тип, в который можно преобразовать исходный тип, в том числе через определенные пользователем преобразования, и запрос будет транслирован в вызов .Cast или .Select соответственно.Почему? Без понятия. Но поведение VB очень последовательно. Например, когда вы набираете
For Each x As T In collection, часть As T может вызвать любое разрешенное преобразование или не вызвать вообще ничего. Так что поведение переменных диапазона From и операторов As согласуется с циклами For Each (и действительно, со всеми операторами As).
71-75. Оператор Select вообще не требуется, может появляться в середине запроса, может появляться несколько раз и может объявлять несколько переменных диапазона с неявными или явными именами
Например:
From x In y Where x > 10допустимо. Давайте просто скажем, чтоSelectнеявный.From x In y Select x Where x > 10абсолютно нормально.From x In y Select xна самом деле то же самое, что иFrom x In y Select x = x, гдеxслева — это новая переменная диапазона с именемx, аxсправа — переменная диапазона в области видимости доSelect. ПослеSelectстарыйхвыходит из области видимости.From x In y Select z = x.ToString(), теперьxуходит полностью.From x In y Select x.FirstNameна самом деле то же самое, что написатьFrom x In y Select FirstName = x.FirstName.From x In y Select x.FirstName, x.LastName— это какFrom x In y Select New With {x.FirstName, y.LastName}, за исключением того, что в области видимости нет переменных диапазона. Но с точки зрения результата всего выражения запроса они производят одно и то жеIEnumerable(Of $AnonymousType$), поэтому явно создавать анонимный тип почти никогда не требуется.
Почему? Спросите Аманду Сильвер (Amanda Silver). Но я могу погадать!
- Я предполагаю, что
Selectможет идти где угодно, потому что с точки зрения SQL уже раздражает, чтоSelectне идет первым, а так вы можете поставить его вторым. В изначальном предложении по дизайну LINQ в VB была попытка дать вам возможность ставить Select первым, как в SQL, но с точки зрения инструментария поставить первым From было наилучшим вариантом. - Я предполагаю, что вы можете его опустить, потому что нет причин требовать обратного.
- Я предполагаю, что вы можете сделать
Selectдля нескольких выражений, потому что вы можете сделать это в SQL, и нет никакого смысла делать это как-то по-другому и не нужно использовать явно синтаксис анонимных типов. Также в VB имеется большой прецедент допустимости comma separated (разделенных запятой) списков чего-либо. - Я предполагаю, что
Selectнеявно объявляет имена, потому что если бы этого не было, вам пришлось бы повторять имена, и вам нужны имена, потому что, если бы не было имен, вам было бы не на что ссылаться в последующих инструкциях, и проекция подмножеств столбцов из таблиц баз данных — крайне распространенный сценарий.
Имеет ли это значение? Эти различия, на мой взгляд, важны из-за ошибки, которая иногда выдается и которую сложно понять в ситуациях, вроде такой:
исходный код на GitHub
BC36606: Range variable name cannot match the name of a member of the 'Object' class и BC30978: Range variable '…' hides a variable in an enclosing block or a range variable previously defined in the query expression — обе могут возникнуть в результате непреднамеренного объявления переменной диапазона с тем же именем, что и у члена Object, или локальной переменной в области видимости вне запроса, обязательно в сценарии, когда запрос выбирает одно значение, которое предполагается анонимным. Проблема решается заключением в скобки выражения (n.ToString()), потому что это предотвращает неявное именование. Я бы хотел, чтобы однажды язык перестал сообщать об этой ошибке в этом распространенном случае.76+. Вызов метода и разрешение перегрузки отличаются
Я пытался уместить все это в одну страницу. Мне… не хватило… сил. Опубликую… оставшиеся 20-25 различий на следующей неделе (на момент перевода автор не сдержал обещание — прим.пер.).
Минутка рекламы. 15-16 мая в Санкт-Петербурге состоится конференция для .NET-разработчиков DotNext 2019 Piter. Будет множество докладов, касающихся деталей работы и внутреннего устройства платформы. Программа всё ещё находится на этапе формирования, но около половины докладов уже известны. На официальном сайте можно ознакомиться с программой и приобрести билеты.Ссылка на оригинал.
Комментариев нет:
Отправить комментарий